Sparse Index DynamoDB
Sebuah sparse index adalah secondary index yang hanya menampung Item yang membawa atribut keynya — sehingga subset kecil nan hot dari tabel raksasa menjadi collection-nya sendiri yang sudah terprafilter dan siap di-query.
Anda punya jutaan baris tetapi query yang Anda jalankan sepanjang hari menyentuh irisan kecil: tiket support yang terbuka, invoice yang belum dibayar, akun yang ditandai untuk peninjauan.
Memfilter irisan itu tetap men-scan seluruh tabel dan menagih Anda untuk setiap pembacaan. Sebuah sparse index membuat index itu sendiri yang kecil.
Apa itu sparse index di DynamoDB?
Sparse index adalah secondary index yang hanya menampung Item yang membawa atribut keynya. Karena DynamoDB melewati Item yang tidak memiliki key tersebut, Anda menciptakan key yang hanya ditulis oleh Item yang diinginkan — tiket terbuka, invoice belum lunas — dan index pun menjadi tepat subset itu. Query kemudian membaca hanya index itu, tanpa filter, tanpa read capacity yang terbuang.
- Secondary index hanya meng-index Item yang punya keynya. Hilangkan key pada sebuah Item dan ia tak pernah masuk index — tanpa placeholder, tanpa baris null.
- Jadi Anda menciptakan key yang hanya dibawa Item yang diinginkan. Tulis ia pada Item yang Anda query, hapus ia pada sisanya. Index menjadi tepat subset itu.
- Query membaca hanya subset, tanpa filter. Ukurannya mengikuti himpunan hot yang kecil, bukan total tabel.
REMOVEadalah tuasnya, bukan mengosongkan. String kosong tetaplah nilai dan tetap di-index — Anda harus menghapus atributnya.
Masalahnya: memfilter tidak menghemat pembacaan
Datang dari SQL, Anda berasumsi klausa WHERE mempersempit pekerjaan.
FilterExpression DynamoDB tidak. Ia berjalan setelah Item dibaca, bukan
sebelumnya.
Menurut AWS Developer Guide, memfilter "tidak mengurangi jumlah read capacity yang dikonsumsi" — Anda membayar untuk setiap Item yang diperiksa, lalu membuang yang tak cocok.
Jadi jika 50 dari 5 juta tiket Anda terbuka, sebuah Query/Scan berfilter membaca
melewati jutaan untuk menyerahkan 50 itu.
Itulah footgun di balik setiap utas "kenapa scan saya begitu mahal"; query vs scan punya gambaran biaya lengkapnya.
Sebuah sparse index mengelaknya dengan membuat index itu sendiri kecil.
Cara kerja sparseness
Sebuah secondary index hanya meng-index Item yang benar-benar punya atribut key index tersebut.
Dokumen AWS tentang global secondary index menyatakannya jelas: "sebuah global secondary index hanya berisi Item yang punya key attribute yang didefinisikan untuk index tersebut."
Lewatkan partition key (atau sort key) GSI pada sebuah Item dan DynamoDB sekadar tak menulisnya ke index. Tanpa placeholder, tanpa baris null — Item itu absen.
"Absen secara default" itulah seluruh triknya. Jangan index atribut status yang
dibawa setiap Item. Ciptakan atribut yang hanya dibawa Item yang ingin Anda
query.
Index kemudian menjadi daftar bersih dari tepat Item-Item itu, dan sebuah Query
terhadapnya membaca hanya mereka — tanpa filter, tanpa kapasitas terbuang.
Bayangkan tabel dasar memberi makan index, di mana hanya Item yang membawa key yang menyeberang:
Hanya Item (open) yang ber-key yang direplikasi ke index; Item closed tak pernah masuk.
Ini adalah pola pikir pembentukan-key yang sama dengan single-table design: key adalah alat yang Anda bangun untuk pola akses tertentu, bukan cermin setia dari data Anda.
Contoh nyata: "tiket open saja"
Ambil sebuah tabel tiket-support. Tabel dasar berkey untuk mengambil tiket berdasarkan id dan mendaftar tiket seorang customer:
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
Sepanjang masa pakai tabel, sebagian besar tiket berakhir closed. Tetapi query dashboard yang dipakai agen Anda sepanjang hari adalah "tampilkan setiap tiket open, terlama lebih dulu" — beberapa ratus baris yang bersembunyi di antara jutaan.
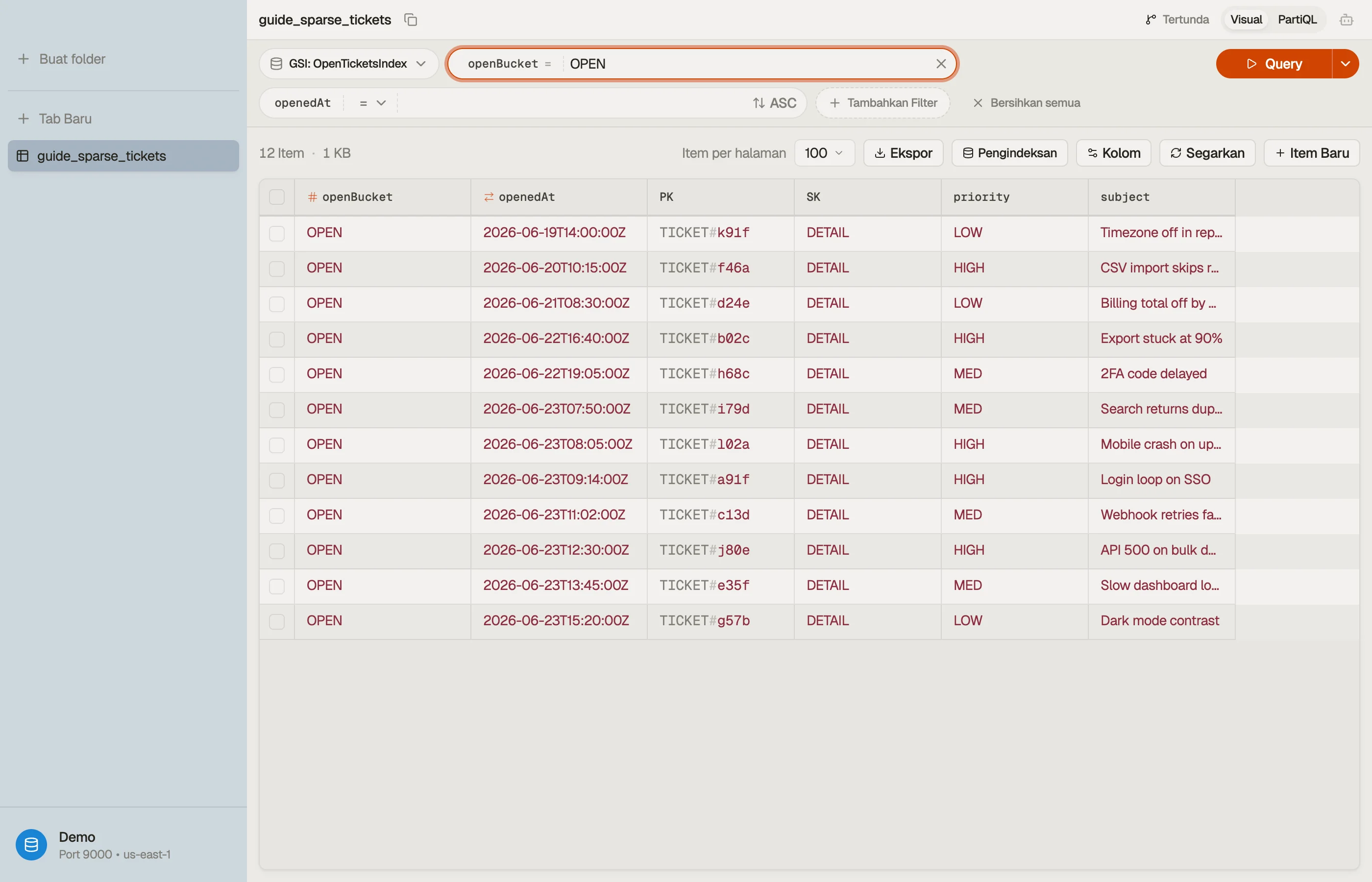
Langkah sparse-index: definisikan sebuah GSI dengan partition key openBucket dan
sort key openedAt, dan hanya tulis openBucket pada tiket open. Setel saat
tiket dibuat; REMOVE ia saat tiket selesai.
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← open: dalam index |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← open: dalam index |
| TICKET#77de | DETAIL | (absen) | 2026-05-30T11:02:00Z | ← closed: TIDAK dalam index |
Tiket a91f dan b02c membawa openBucket, jadi mereka hidup di GSI. Tiket 77de
telah diselesaikan dan openBucket-nya dihapus, jadi ia diam-diam keluar.
Dashboard kini menjadi satu query murah:
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # terlama lebih duluIni membaca hanya tiket open. Saat tiket closed, index menyusut dengan sendirinya — ukurannya mengikuti populasi open, tak pernah totalnya.
Satu nilai partition statis ("OPEN") baik-baik saja di sini justru karena
himpunannya tetap kecil. Himpunan open yang besar akan butuh partition key
ter-shard, tetapi index "subset kecil" adalah persis tempat satu nilai menjadi
pilihan yang tepat.
Transisi yang membuatnya bekerja adalah sebuah update expression tunggal — menghapus atribut saat tiket selesai.
Prototipekan klausa REMOVE itu dan kondisi key bertipe untuk sisi baca di
DynamoDB Expression Builder, alih-alih
merakit sendiri ExpressionAttributeNames dan placeholder :val.
Lakukan di DynoTable
Bagian sulit dari sparse index bukanlah pembacaannya — melainkan melihat Item mana yang berhasil masuk index versus mana yang diam-diam keluar.
DynoTable membiarkan Anda mengalihkan tampilan tabel ke secondary index dan melihat
persis subset yang terisi. Jadi Anda bisa memastikan tiket yang diselesaikan
benar-benar meninggalkan open-tickets-index alih-alih tertinggal dengan key
basi.


Jebakan dan langkah berikutnya
Beberapa hal yang perlu diwaspadai:
- Hapus keynya, jangan kosongkan. String kosong tetaplah nilai, dan DynamoDB
akan meng-index Item yang
openBucket-nya"". Untuk mengeluarkan Item dari index Anda harusREMOVEatributnya — menyetelnya ke nilai falsy malah mempertahankannya. - Index bersifat eventually consistent. GSI diperbarui secara asinkron, jadi tiket yang baru saja diselesaikan bisa sesaat masih muncul — pembacaan GSI hanya mendukung eventual consistency. Jangan percayai ia untuk "apakah tiket ini open sekarang juga".
- Perhatikan atribut yang diproyeksikan. Sebuah
Querypada index hanya mengembalikan atribut yang diproyeksikan ke dalamnya. Jika dashboard butuh subject dan priority, proyeksikan mereka — atau bayarGetItemtambahan untuk Item dasar lengkap. - Ini adalah kekuatan GSI, bukan LSI. Local secondary index berbagi partition key tabel dasar dan tak bisa menjatuhkan Item secara selektif dengan cara ini. GSI vs LSI menguraikan trade-off-nya.
Sparse index adalah salah satu ide tertua dalam model ini. Makalah asli Amazon Dynamo 2007 membangun store di sekitar melayani pola akses yang diketahui dan bervolume tinggi dengan murah.
Sparse index adalah persis itu: bentuk key agar query umum tak membaca apa pun yang tak dibutuhkannya.
Untuk membangun dan menginspeksi satu secara nyata, unduh DynoTable, arahkan ke tabel Anda, dan balikkan tampilan data ke sparse GSI Anda — saksikan subset diperbarui saat Item memperoleh dan kehilangan key index.