Relasi Many-to-Many di DynamoDB
Seorang student mendaftar di banyak course; sebuah course menampung banyak student.
Di SQL Anda meraih join table dan sebuah JOIN empat arah.
DynamoDB tidak punya join, jadi relasinya harus hidup di dalam key — dan
triknya adalah menyimpan setiap edge enrollment dalam bentuk yang bisa di-Query
langsung oleh kedua sisi.
Panduan ini menelusuri masalah student ↔ course dari ujung ke ujung: pola akses, pola adjacency-list yang menyelesaikannya, sebuah key schema orisinal yang bisa Anda salin, dan cara membaca kembali kedua arah tanpa pernah men-scan tabel.
Bagaimana cara memodelkan relasi many-to-many di DynamoDB?
DynamoDB tidak memiliki join, sehingga Anda memodelkan relasi many-to-many dengan pola adjacency-list: simpan setiap tautan sebagai Item edge tersendiri yang diberi key dari salah satu sisi, lalu tambahkan GSI terbalik yang menukar key tersebut. Satu edge, ditulis sekali, lalu menjawab query dari kedua arah dengan murah.
- Simpan setiap enrollment sebagai Item edge tersendiri, bukan atribut list pada salah satu sisi.
- Beri key edge berdasarkan student (
PK = STU#…,SK = ENROLL#CRS#…) agar satuQuerymengembalikan seluruh daftar course seorang student. - Tambahkan GSI terbalik yang menukar peran (
GSI1PK = CRS#…) agar edge yang sama juga menjawab "siapa saja yang ada di course ini?". - Satu edge, ditulis sekali, dibaca murah dua arah — itulah seluruh permainannya.
Bingkai pola aksesnya lebih dulu
Pemodelan DynamoDB mengutamakan pola akses: Anda menentukan pembacaan sebelum memilih satu nama atribut pun. Relasi many-to-many hampir selalu punya dua pembacaan simetris ditambah lookup entitas:
- Ambil profil seorang student, dan daftar setiap course yang diikuti student itu.
- Ambil metadata sebuah course, dan daftar setiap student yang terdaftar di course itu.
- Cari satu edge enrollment tunggal — untuk memperbarui nilai atau keluar dari course.
Rasa sakitnya: kedua pembacaan daftar itu menunjuk ke arah berlawanan melintasi
himpunan edge yang sama. Desain naif melayani salah satunya dengan murah dan
memaksa sebuah Scan untuk yang lain — footgun persis yang dibahas dalam
Query vs Scan.
Tugasnya adalah membuat kedua arah menjadi satu Query.
Gunakan pola adjacency-list
Panduan DynamoDB sendiri untuk relasi adalah adjacency list: modelkan setiap relasi sebagai Item yang partition keynya adalah satu endpoint dan sort keynya adalah endpoint lainnya.
AWS mendokumentasikan ini pada halaman Best Practices for Managing Many-to-Many Relationships dari DynamoDB Developer Guide.
Mengapa key dan bukan tabel kedua? Karena primitif yang DynamoDB berikan adalah
sebuah Query terhadap satu partition.
Sebuah Query membaca rentang nilai sort-key yang menyatu di bawah satu partition
key dalam satu operasi yang ditagih — itulah satu-satunya "join" yang ditawarkan
mesin ini.
Untuk mendapatkan relasi yang dibaca murah dari kedua sisi, Anda menggandakan edge: tulis sekali dengan key student, lalu gunakan secondary index untuk memproyeksikan edge yang sama dengan key course.
Ini adalah pemikiran overloaded-key dari Single-Table Design, diterapkan pada sebuah relasi alih-alih hierarki induk-anak.
Bentuknya adalah dua tampilan bertumpuk dari edge yang sama — tabel dasar berkey student, GSI terbalik berkey course:
Setiap edge ditulis sekali pada tabel dasar dan diproyeksikan ke dalam GSI dengan
keynya ditukar, sehingga sebuah Query terhadap partition mana pun membaca relasi
dengan murah.
Garis keturunannya kembali ke makalah Amazon Dynamo paper tahun 2007: partition key adalah satuan distribusi, dan akses single-key adalah jalur cepat.
Relasi di DynamoDB adalah latihan membengkokkan pembacaan many-to-many ke jalur cepat itu.
Kerjakan contohnya: student ↔ course
Gunakan satu tabel dengan key generik, PK dan SK, dan kodekan tipe entitas di
dalam nilainya. Edge enrollment adalah jantungnya:
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
Satu Query PK = "STU#a91" mengembalikan profil student dan setiap enrollment
dalam satu pembacaan. Persempit dengan SK begins_with "ENROLL#" untuk mendapatkan
hanya edge course saja. Itu menyelesaikan "daftar course seorang student".
Tetapi "daftar student sebuah course" menunjuk ke arah lain — dan tabel dasar tak bisa menjawabnya, karena id student ada di partition key, bukan sort key.
Tambahkan sebuah global secondary index terbalik yang menukar peran. Beri Item
edge pasangan GSI1PK/GSI1SK generik yang menampung course di sisi partition dan
student di sisi sort:
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
Kini Query GSI1 WHERE GSI1PK = "CRS#math204" mendaftar setiap student di course
itu — pembacaan yang tak bisa dilayani tabel dasar. Satu Item edge, ditulis sekali,
menjawab kedua arah.
Ia harus berupa GSI, bukan LSI: partition course sepenuhnya berbeda dari partition student, dan sebuah LSI berbagi partition key tabel dasar.
Index ini membentang banyak partition, jadi ia harus global — lihat GSI vs LSI.
Satu catatan: GSI di DynamoDB diisi secara asinkron. Sebuah enrollment yang
betul-betul baru bisa butuh sesaat untuk muncul di arah CRS#….
Perlakukan pembacaan roster course sebagai eventually consistent — yang ditegaskan Developer Guide secara eksplisit untuk global secondary index.
Tulis dan baca di DynoTable
Menulis enrollment berarti menyetel empat atribut key plus data edge itu sendiri.
Kondisi yang mencegah seorang student mendaftar dua kali di course yang sama adalah
guard attribute_not_exists(PK) pada composite key.
Itu persis jenis kondisi yang bisa Anda rakit secara visual dengan
DynamoDB Expression Builder alih-alih menulis
tangan ExpressionAttributeNames dan nilai placeholder.
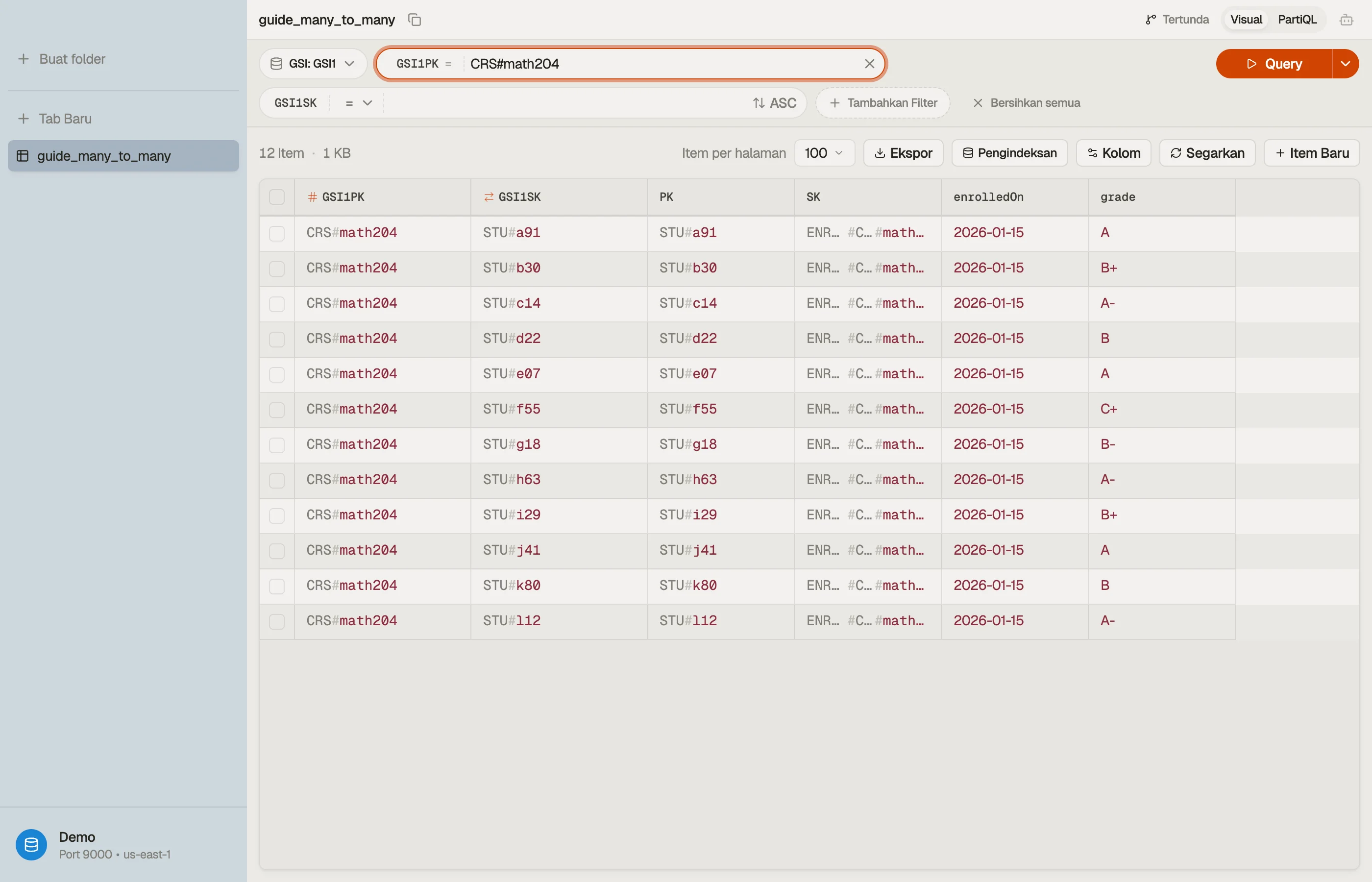
Di DynoTable Anda mengarahkan sebuah Query ke GSI1, menyetel
GSI1PK = "CRS#math204", dan rosternya kembali sebagai tabel yang bisa Anda baca,
urutkan, dan edit di tempat — kedua arah relasi dapat ditelusuri dari satu schema.


Jebakan dan langkah berikutnya
- Jangan simpan salah satu sisi sebagai atribut list. Sebuah array
courseIdspada Item student terasa rapi sampai sebuah course butuh rosternya, array menyentuh batas Item 400 KB, atau dua enrollment berlomba dan saling menimpa. Item edge diskret menskala dan diperbarui secara independen. - Jaga data edge tetap di edge.
gradedanenrolledOnenrollment berada di Item edge, tidak digandakan ke student atau course — ada tepat satu baris per pasangan (student, course) yang diperbarui. - Perhatikan propagasi GSI. Arah inverted-index bersifat eventually consistent, jadi pembacaan tepat setelah enrollment bisa tertinggal sepersekian detik.
- Proyeksikan hanya yang dibutuhkan roster. Proyeksi
KEYS_ONLYatau yang sempit menjaga GSI tetap kecil saat tampilan roster hanya butuh id.
Untuk mendalami pola-pola di sekelilingnya, baca Single-Table Design untuk overloaded key dan GSI vs LSI untuk kapan inverted index harus global.
Lalu unduh DynoTable untuk memodelkan schema student ↔ course secara nyata — tulis edge-nya, bangun kondisi dengan Expression Builder, dan query kedua arah relasi tanpa satu scan pun.