Cara Memodelkan Data di DynamoDB
Di SQL Anda memodelkan entitas dan relasi terlebih dahulu, lalu mempercayai query planner untuk merakit apa pun yang Anda minta belakangan. DynamoDB membaliknya. Anda memodelkan pembacaan yang sudah Anda tahu akan Anda lakukan, dan key ada untuk melayaninya.
Tidak ada mesin join dan tidak ada planner yang memilih strategi saat runtime. Sebuah Query membaca satu partition sepanjang satu key, dan itulah seluruh kontrak performanya. Jadi Anda merancang key untuk pola akses yang diketahui, bukan untuk schema yang rapi.
AWS menyatakannya jelas dalam panduan best-practices-nya: "you shouldn't start designing your schema until you know the questions it will need to answer."
Panduan ini menelusuri seluruh prosesnya pada satu domain: sebuah leaderboard game multiplayer yang melacak player, match yang mereka mainkan, dan ranking per-musimnya. Kita bergerak dari daftar pertanyaan ke key schema yang bekerja.
Bagaimana cara memodelkan data di DynamoDB?
Modelkan pembacaan dulu, bukan tabelnya. Daftar setiap query yang dibuat aplikasi, lalu rancang dan agar setiap pertanyaan terselesaikan menjadi satu Query atau GetItem. Tempatkan item yang dibaca bersama dalam satu partition yang sama, jangkau nilai-nilai di sort key, dan tambahkan GSI untuk setiap pola akses yang tidak bisa dilayani tabel dasar.
- Daftar pembacaan dulu, bukan tabel. Pertanyaan adalah spesifikasinya; kata bendanya adalah pengalih perhatian.
- Setiap pertanyaan harus satu
QueryatauGetItem. Jika sebuah pertanyaan butuhScan, modelnya salah. - Item yang berlokasi bersama berbagi partition key; apa pun yang Anda jangkau rentangnya masuk ke sort key.
- Pertanyaan yang tak bisa dijawab tabel dasar mendapat GSI — tak pernah
Scandengan filter.
Langkah 1 — Bingkai masalah sebagai pertanyaan, bukan tabel
Tahan dorongan menggambar tabel players, matches, dan scores. Insting itu adalah kebiasaan SQL, dan di sini ia salah. Sebagai gantinya tuliskan setiap pembacaan yang benar-benar dilakukan aplikasi. Untuk leaderboard kita:
- Ambil profil satu player berdasarkan id.
- Daftar match terbaru seorang player, terbaru lebih dulu.
- Tampilkan N player teratas untuk musim tertentu, berdasarkan rating.
- Cari player berdasarkan handle publiknya (mis. untuk URL profil).
Keempat pertanyaan ini — bukan kata bendanya — adalah spesifikasinya. Masing-masing harus terselesaikan menjadi satu Query (atau GetItem), karena itulah satu-satunya bentuk akses yang dilayani DynamoDB dengan murah pada skala.
Jika sebuah pertanyaan hanya bisa dijawab dengan men-scan tabel, modelnya salah, dan Anda akan merasakannya pada latensi dan biaya — lihat Query vs Scan untuk alasan Scan adalah footgun yang harus dihindari.
Seluruh metodenya adalah pipeline pendek dan berurutan yang Anda jalankan sekali per domain:
Setiap langkah di bawah memetakan ke satu kotak: daftar, enumerasi, rancang key, tambah index untuk sisanya, lalu validasi.
Langkah 2 — Pahami primitif yang Anda modelkan
Sebuah tabel punya partition key (PK) yang memilih di partition fisik mana sebuah Item hidup, dan sebuah sort key (SK) opsional yang mengurutkan Item di dalam partition itu.
Dokumen core-components AWS menyebut pasangan itu primary key Item. Sebuah Query selalu menargetkan tepat satu nilai PK dan bisa range-scan atau memfilter SK — itulah seluruh perkakasnya.
Desain single-partition inilah yang membuat DynamoDB memberikan pembacaan yang dapat diprediksi, berlatensi rendah, dan terpartisi secara horizontal yang pertama kali dijelaskan dalam makalah Amazon Dynamo 2007.
Dua konsekuensi mendorong setiap keputusan di bawah:
- Item yang dibaca bersama harus berbagi partition key agar satu
Querymengembalikan mereka dalam satu request yang ditagih. - Apa pun yang ingin Anda jangkau rentangnya (match terbaru, rating teratas) harus hidup di sort key, karena itulah satu-satunya atribut yang bisa diurut dan dibatasi
Query.
Saat sebuah pertanyaan butuh bentuk akses yang berbeda dari yang disediakan tabel dasar, Anda menambahkan Global Secondary Index — sebuah re-proyeksi tabel di bawah PK/SK berbeda.
(Untuk GSI versus Local Secondary Index, lihat GSI vs LSI.)
Langkah 3 — Rancang key, satu pertanyaan demi satu
Kita gunakan satu tabel dengan atribut key generik yang ditumpangi — pendekatan single-table — karena seorang player dan match-nya dibaca bersama.
Ciptakan prefiks Anda sendiri; di sini PLAYER#, MATCH#, dan SEASON# menandai tipe entitas di dalam key yang selain itu generik.
Pertanyaan 1 dan 2 (profil + match terbaru) berbagi sebuah partition, jadi keduanya bergantung pada PK yang sama:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" mengembalikan profil dan setiap match dalam satu pembacaan. Untuk profil saja, GetItem.
Untuk match terbaru, rangeId begins_with "MATCH#" dengan ScanIndexForward = false menjelajahinya terbaru lebih dulu — timestamp di sort key melakukan pengurutan secara gratis.
Pertanyaan 3 dan 4 tak bisa dijawab dari partition itu — keduanya berputar pada rank musim dan pada handle, yang keduanya bukan PK dasar. Masing-masing mendapat GSI.
Kita tambahkan dua atribut index generik, gsiPartition / gsiSort, dan biarkan setiap Item mengisinya dengan apa pun yang dibutuhkan index itu:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
Kini Query index musim WHERE gsiPartition = "SEASON#2026-Q2" dengan ScanIndexForward = false mengembalikan player yang di-rank berdasarkan rating — itulah leaderboard.
Index kedua berkey HANDLE#… menyelesaikan handle publik menjadi id player dalam satu pembacaan. Satu tabel fisik, empat pola akses single-Query.
Catatan zero-padding pada
RATING#1842: DynamoDB mengurutkan sort key secara leksikografis, bukan numerik, jadi sebuah rating harus di-zero-pad ke lebar tetap (RATING#01842) atau9akan terurut setelah1000. Ini adalah gotcha pemodelan klasik yang layak dibenarkan sejak awal.
Langkah 4 — Validasi modelnya di DynoTable
Sebuah key schema baru memperoleh kepercayaan saat Anda menyaksikan sebuah Query nyata mengembalikan tepat Item yang Anda harapkan dan tak lebih.
Buka tabel di DynoTable, jalankan query leaderboard terhadap index musim, dan pastikan partition kembali ter-rank dan terbatas — tanpa Scan, tanpa pengurutan sisi-klien.

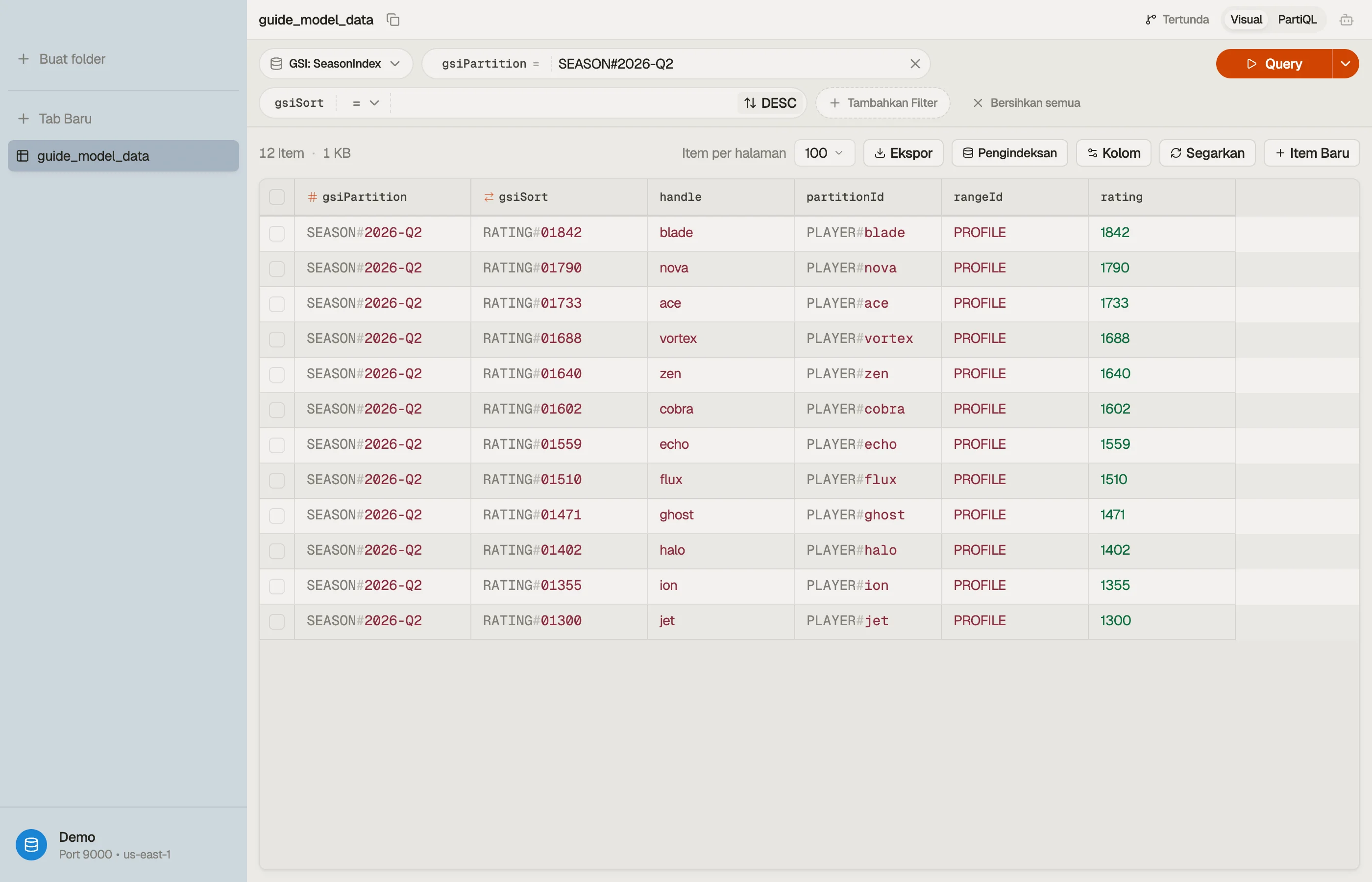

Saat Anda membangun condition expression untuk query ini — begins_with, gsiPartition = :p, binding placeholder :p — biarkan DynamoDB Expression Builder yang mengerjakannya.
Ia menghasilkan KeyConditionExpression, ExpressionAttributeNames, dan ExpressionAttributeValues, jadi reserved word seperti result atau placeholder yang salah ketik tak pernah diam-diam merusak sebuah pembacaan.
Langkah 5 — Jebakan dan langkah berikutnya
Beberapa jebakan untuk dicek sebelum Anda merilis modelnya:
- Jangan modelkan relasi yang tak pernah Anda baca bersama. Satu GSI per pertanyaan itu murah; GSI sia-sia adalah biaya berulang. Tambahkan index dari daftar pertanyaan, bukan secara spekulatif.
- Perhatikan panas partition. Jika satu PK (player selebritas, satu musim hot) menyerap sebagian besar trafik, partition itu bisa throttle. Sebarkan penulisan dengan suffix shard saat sebuah key terbukti hot — AWS membahas ini di bawah desain partition-key.
- Zero-pad dan ISO-8601-kan segala yang numerik atau temporal dalam sort key, agar pengurutan leksikografis cocok dengan urutan yang Anda maksud.
- Pertanyaan baru = key atau index baru, tak pernah
Scan. Saat pola akses yang benar-benar baru muncul belakangan, perluas key-nya; jangan menutupinya dengan filter.
Modelkan pertanyaannya dulu, rancang key agar masing-masing menjadi satu Query, lalu buktikan.
Coba DynoTable untuk menelusuri tabel Anda, menjalankan query ini terhadap tabel dasar dan GSI secara berdampingan, dan menyaksikan pola akses yang Anda rancang mengembalikan tepat apa yang Anda rencanakan.