DynamoDB'de Bire-Çok İlişkiler
Bir SaaS denetim düzleminin neredeyse her zaman bir kapsama hiyerarşisi vardır: bir
workspace birçok projeye sahiptir. SQL'de projeler tablosuna bir
workspace_id yabancı anahtarı koyup JOIN yapardın.
DynamoDB'nin join'leri ve yabancı anahtarları yoktur, bu yüzden ilişkinin
anahtar şemasının kendisinde yaşaması gerekir. Doğru yapılırsa, "bir workspace'i
ve içindeki her projeyi yükle" işlemi, bir okuma artı bir takip taraması yerine tek
bir Query haline gelir.
DynamoDB'de bire-çok ilişkiyi nasıl modellersiniz?
Üst öğeye ve tüm alt öğelerine aynı 'i verin; böylece tek bir paylaşırlar ve onları sort key ile ayırt edin. DynamoDB'nin join'leri ve yabancı anahtarları yoktur, dolayısıyla ilişki anahtar şemasının kendisinde yaşar. Üst öğeyi ve tüm alt öğeleri yüklemek, join yerine tek bir Query haline gelir.
- Varlıkları değil, okumaları modelle. Bire-çok ilişki yalnızca "bir workspace'in projelerini listele" işlemine hizmet etmek için vardır — anahtarları o sorgunun etrafında şekillendir.
- Üst öğeyi alt öğenin partition key'ine kodla. Workspace'e ve tüm projelerine aynı partition-key değerini ver, böylece tek bir item collection içinde yer alırlar.
- O zaman liste okuması tek bir
Query'dir. Üst öğe artı keyfi sayıda alt öğe, tek bir faturalandırılan çağrıda geri gelir — join yok, ikinci tur yok. - Sıcak partition'a dikkat et. Tek bir devasa tenant tüm trafiğini bir partition'da yoğunlaştırır; çok büyük bir workspace, parçalanmış (sharded) bir anahtar ve bir fan-out okuması gerektirebilir.
Önce erişim deseni
DynamoDB modelleme, varlık öncelikli değil erişim-deseni önceliklidir — single-table tasarımın ardındaki aynı disiplin. Herhangi bir anahtar seçmeden önce, uygulamanın gerçekte yaptığı okumaları yaz:
- Bir workspace'in ayarlarını al.
- Bir workspace'teki her projeyi listele, en yenisi ilk.
- Belirli bir projeyi id ile al.
"Bir workspace, birçok proje" ilişkisi yalnızca 2 numaralı okuma yüzünden önemlidir. Bir workspace'in projelerini birlikte listelemen hiç gerekmeseydi, ilişkiyi hiç modellemezdin — projeleri bağımsız olarak saklardın.
Yani soru hiçbir zaman soyut anlamda "bire-çok ilişkiyi nasıl temsil ederim?" değildir. "Bu ilişkinin hangi sorgulara hizmet etmesi gerekir?" sorusudur. Buna yanıt ver, sonra anahtarları bunun etrafında şekillendir.
Neden burada bir yabancı anahtar işe yaramaz
DynamoDB'de her GetItem ve Query bir partition key hedefler ve servis,
öğeyi tutan partition'ı bulmak için o anahtarı hash'ler.
AWS bunu Core Components dokümanlarında doğrudan söyler: partition-key değeri, verinin nerede yaşadığına karar veren dahili bir hash fonksiyonuna girdidir.
Bu hash tabanlı yerleştirme, orijinal 2007 Dynamo: Amazon's Highly Available Key-value Store makalesinden gelen mirastır; burada tutarlı hashing anahtarları düğümlere dağıtır.
Bir proje öğesi üzerindeki çıplak bir workspace_id attribute'u o mekanizmaya
görünmezdir — DynamoDB onu "takip edemez".
İlgili öğeleri tek bir istekte getirmek için, üst öğenin kimliği projenin
partition key'ine kodlanmalıdır, böylece bir workspace'in tüm öğeleri aynı
partition'a hash'lenir ve tek bir Query onları süpürebilir.
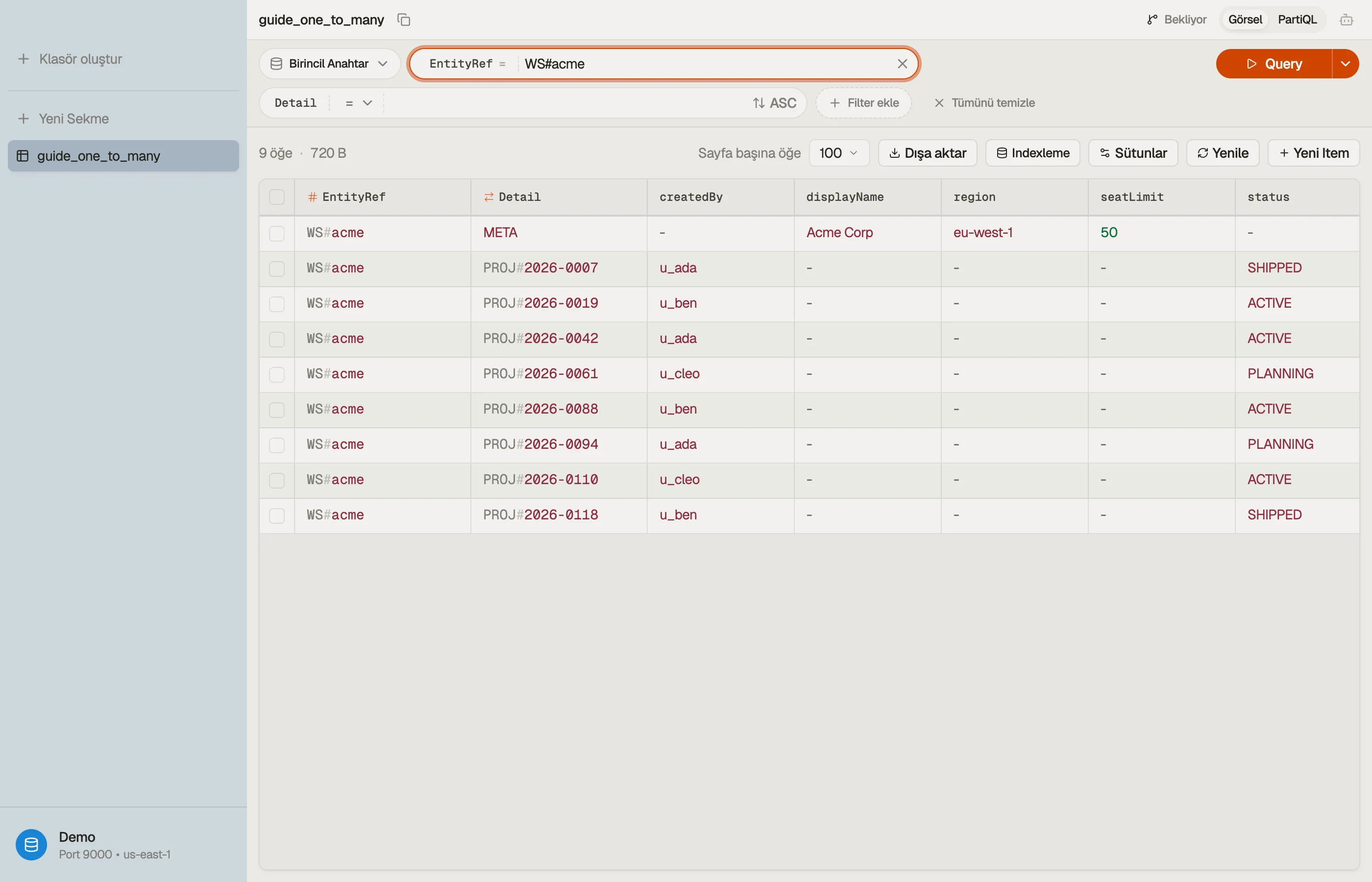
İşlenmiş örnek: workspace'ler ve projeler
Genel, aşırı yüklenmiş (overloaded) bir anahtar şeması kullan. Partition key'e
EntityRef, sort key'e Detail adını ver. Workspace kimliği, hem workspace
öğesi hem de altındaki her proje için EntityRef'e girer:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
Workspace ve tüm projeleri EntityRef = "WS#acme" değerini paylaşır, böylece tek
bir partition üzerinde birlikte yaşayan tek bir item collection oluştururlar.
Detail sort key onları ayırır: META workspace kaydıdır ve her proje, projelerin
doğal olarak sıralanması için sıfırla doldurulmuş, zaman sıralı bir id ile bir
PROJ# öneki taşır.
Görsel olarak, üst öğe ve alt öğeleri tek bir partition içinde, sort key'e göre sıralanmış şekilde üst üste yığılır:
EntityRef = "WS#acme" üzerinde tek bir Query, tüm yığını — üst öğe artı her alt
öğe — tek bir okumada süpürür.
Şimdi üç erişim deseninin her biri tek bir çağrıya indirgenir:
- Workspace ayarları —
GetItem(EntityRef="WS#acme", Detail="META"). - Projeleri en yeniden başlayarak listele —
Query(EntityRef="WS#acme")ileDetail begins_with "PROJ#", azalan sırada çalıştırılır (ScanIndexForward = false). - Tek bir proje —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042").
İkincisi tüm mesele: üst öğe ve keyfi sayıda alt öğe, tek bir faturalandırılan
Query ile geri gelir, join yok, ikinci tur yok. Bunu bir yabancı-anahtar
attribute'u ve bir Scan ile yapamazsın.
O begins_with koşulunu elle yazmak zahmetlidir — key-condition ve
projection-expression söz dizimi can yakar.
DynamoDB Expression Builder,
KeyConditionExpression'ı, #name/:value placeholder eşlemelerini ve
çalıştırmaya hazır bir SDK parçacığını üretir, böylece dilbilgisiyle uğraşmazsın:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }Item collection'ı DynoTable'da incele
Bu düzenin getirisi görseldir: bir EntityRef'i paylaşan her satır, workspace artı
alt öğeleridir; yan yana otururlar.
DynoTable onları gruplar, böylece bire-çok ilişkiyi ayrı tablolar arasında tahmin etmek yerine tek bir bitişik blok olarak görürsün.


Tuzaklar ve alternatif şekil
Dikkat edilecek birkaç şey:
- Sıcak partition'lar. Bir workspace'in her öğesi tek bir partition'da yaşar,
bu yüzden tek bir çok büyük veya çok yoğun tenant trafiği yoğunlaştırır. AWS'nin
tanımladığı adaptive capacity
davranışı orta düzeydeki çarpıklığı emer, ancak milyonlarca projesi olan bir
workspace parçalanmış bir anahtar (örn.
WS#acme#01 … #10) ve bir fan-out okuması gerektirebilir. - Item-collection boyutu. Bir local secondary index varsa, tek bir partition'ın item collection'ı 10 GB ile sınırlıdır; LSI olmadan böyle bir sınır yoktur. Burada index türlerini tartıyorsan, bkz. GSI ve LSI.
Query'ye uzan, aslaScan'e değil. Tüm tasarım, bir partition'ıQueryedebilmen için vardır. "Bir workspace'in projelerini bul" diye filtreli birScan'e geri dönmek modeli çöpe atar ve tüm tabloyu okur — Query ve Scan'de işlenen tuzak.
Gerçekten workspace'ler arası projeleri listelemen gerekiyorsa (diyelim ki
küresel olarak tüm status = ACTIVE projeler), temel tablo buna yanıt veremez —
partition key'i workspace kapsamlıdır.
Bu, projeleri farklı bir attribute üzerinden yeniden bölümleyen bir secondary index'in işidir, bu ilişkiyi yeniden şekillendirmenin değil.
Sonraki adımlar
Erişim desenlerini modelle, üst öğeyi alt öğenin partition key'ine kodla ve
bire-çok okuması tek bir Query olsun. Anahtar koşulunu
DynamoDB Expression Builder ile oluştur ve
doğrula.
Sonra bu şemayı yüklemek, workspace→projeler item collection'ını canlı taramak ve her sorgunun tam olarak bir okuma yaptığını doğrulamak için DynoTable'ı indir.