DynamoDB Komşuluk Listesi (Adjacency List) Deseni
Bir graf yalnızca düğümler ve kenarlardan ibarettir ve komşuluk listesi
(adjacency list) deseni her ikisini de tek bir tabloda sıradan öğeler olarak
saklar. Her kenar, bölüm anahtarı kaynak düğüm, sıralama anahtarı hedef olan bir
satır olur. Bir bölümü sorgulamak her komşuyu listeler — bir join tablosu
üzerindeki bir JOIN'in DynamoDB karşılığı.
DynamoDB komşuluk listesi (adjacency list) deseni nedir?
Komşuluk listesi (adjacency list) deseni, bir grafı tek bir tabloda kenar öğeleri olarak modeller: her ilişki (A, B'yi takip eder) bölüm anahtarında kaynak, sıralama anahtarında hedef olacak şekilde anahtarlanmış bir satırdır. Bir bölümü sorgulamak her komşuyu listeler ve ters çevrilmiş bir GSI ilişkiyi tersine çevirir — join yok, scan yok, her iki yön de tek bir sorguda.
- Kenarlar öğelerdir. Her ilişkiyi (A kullanıcısı B kullanıcısını takip eder) kaynak bölüm anahtarında, hedef sıralama anahtarında olacak şekilde anahtarlanmış kendi öğesi olarak modelleyin.
- Bir yön bedava; diğeri bir GSI ister. Temel tablo "A kimi takip ediyor?" sorusunu yanıtlar. Ters çevrilmiş bir indeks "A'yı kim takip ediyor?" sorusunu yanıtlar.
- Join yok, scan yok. Her iki yön de bilinen bir bölüme karşı tek bir
Query'dir — asla tam tablolu birScandeğildir. - Çoktan çoğa ilişki ilkelidir. Takipler, üyelikler, beğeniler, arkadaşlıklar — bir varlığın diğer birçoğuna bağlandığı her graf bu biçime uyar.
Bunu erişim desenleri olarak çerçeveleyin
SQL'den geliyorsanız, bir takip grafiği bir join tablosudur:
follows(follower_id, followee_id). Birinin takipçilerini listelemek için bir
sütunu indekslersiniz; kimi takip ettiğini listelemek için diğerini. DynamoDB'de
join yoktur, bu yüzden anahtarları her okumaya doğrudan hizmet edecek şekilde
tasarlarsınız.
Önce okumaları yazın. Bir sosyal takip grafiği için:
- A kullanıcısı kimi takip ediyor? (onun takip ettikleri listesi)
- A'yı kim takip ediyor? (onun takipçileri listesi)
- A, B'yi takip ediyor mu? (tek bir nokta araması)
Anahtarlar yalnızca o listeyi yanıtlamak için vardır. Onları doğru yapın ve her
okuma tek bir Query ya da GetItem olsun.
Kenarları öğeler olarak modelleyin
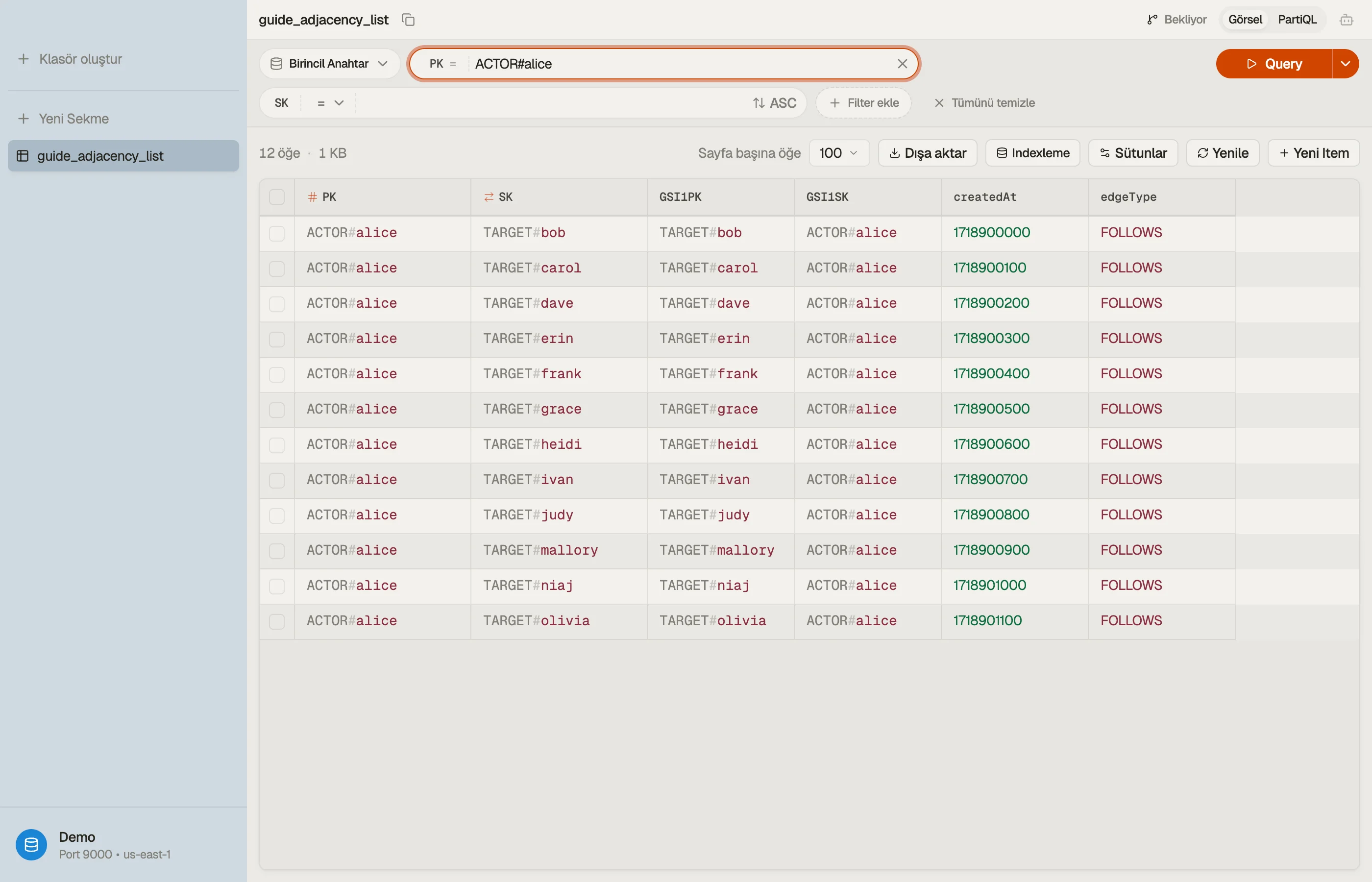
Tablonun birden fazla varlık türü tutabilmesi için genel anahtar adları kullanın ve düğüm türünü değerde kodlayın. Bir takip kenarı şöyle görünür:
| PK | SK | createdAt | edgeType |
|---|---|---|---|
| ACTOR#alice | TARGET#bob | 1718900000 | FOLLOWS |
| ACTOR#alice | TARGET#carol | 1718900100 | FOLLOWS |
| ACTOR#dave | TARGET#bob | 1718900200 | FOLLOWS |
PK = ACTOR#alice kenarın kaynağıdır; SK = TARGET#bob onun kimi takip ettiğidir.
Tek bir Query PK = "ACTOR#alice", Alice'in takip ettiği her hesabı tek bir
faturalandırılan okumada döndürür — onun tüm takip ettikleri listesi, join yok.
Her kenar bir kez, "kimi takip ediyorum" yönünde yazılır. Ters yön ("beni kim takip ediyor") temel tablonun yanıtlayamadığı kısımdır — şimdilik.
Diğer yönü bir GSI ile gezin
Temel tablo kaynak-önce anahtarlanmıştır, bu yüzden taramadan "Bob'u kim takip ediyor?" sorusunu yanıtlayamaz. Anahtarları ters çeviren bir global secondary index ekleyin: hedefi indeks bölüm anahtarına, kaynağı indeks sıralama anahtarına yansıtın.
| GSI1PK | GSI1SK | (temel öğe) | |
|---|---|---|---|
| TARGET#bob | ACTOR#alice | ACTOR#alice → TARGET#bob | |
| TARGET#bob | ACTOR#dave | ACTOR#dave | → TARGET#bob |
| TARGET#carol | ACTOR#alice | ACTOR#alice → TARGET#carol |
Artık Query GSI1 WHERE GSI1PK = "TARGET#bob", Bob'u takip eden herkesi —
alice ve dave — tek bir okumada listeler. Aynı kenar öğesi her iki yöne de
hizmet eder: temel tablo takip edilenler, indeks ise takipçiler. Her kenarı bir
kez yazar ve her iki sorguyu da bedava elde edersiniz.
Bu, AWS'nin çoktan çoğa ilişkileri ve graf verisini modellemek için DynamoDB en iyi uygulamalar kılavuzunda belgelediği desenin tam olarak aynısıdır — kenarları öğeler olarak saklayın, ardından ilişkiyi tersine çevirmek için bir GSI kullanın.
Tek bir kenarı ucuza kontrol edin
"Alice, Bob'u takip ediyor mu?" iki listenin hiçbirine ihtiyaç duymaz. Kenar
PK = ACTOR#alice, SK = TARGET#bob ile anahtarlandığından, doğrudan bir
GetItem'dır — DynamoDB'nin sunduğu en ucuz okuma, ne Query ne indeks.
Takibi idempotent yazmak ve çift sayımı önlemek için, PutItem'ı kenarın zaten var
olmadığına dair bir koşulla koruyun:
attribute_not_exists(PK)O koşulu — ve marshalled anahtar değerlerini —
DynamoDB Expression Builder ile, elle
ConditionExpression ve ExpressionAttributeValues yazmak yerine
oluşturabilirsiniz.
Bunu DynoTable'da yapın
Tabloya göz attığınızda, bir aktöre ait kenarlar tek bir öğe koleksiyonu olarak tek bir bölüm anahtarı altında üst üste yığılır ve GSI görünümüne geçmek ters çevrilmiş takipçi listesini gösterir — ilişkinin iki yarısı yan yana.


Tuzaklar
Ünlü bölüm. Milyonlarca takipçisi olan bir kullanıcı, her takipçi kenarını tek
bir GSI1PK = TARGET#<star> bölümü altında yoğunlaştırır. O koleksiyonun okumaları
sayfalanır ve sıcak çalışabilir. Fan-out ağırlıklı graflar için, sıcak anahtarı
sharding'leyin (örn. TARGET#bob#0..N) ya da tüm listeyi yeniden okumamak için
sayıları denormalize edin.
Sayıları kenarda saklamak. Bir takipçi sayısı bir kenar değildir — onu her profil görüntülemesinde tüm bölümü okuyup sayarak türetmeyin. Kullanıcı öğesinde bir sayaç niteliği tutun ve onu kenarla işlemsel (transactional) olarak güncelleyin.
Burada ters yazmanın gerekmediğini unutmak. Klasik bir komşuluk listesi varyantı, kenarı kimlikler değiştirilerek iki kez yazar. Anahtarı ters çeviren bir GSI ile onu bir kez yazar ve indeksin tersini materyalize etmesine izin verirsiniz — daha az yazma, iki kopya arasında kayma yok.
Sonraki adımlar
Komşuluk listesi, tek tablo tasarımının ilişki yapı
taşıdır; ters çeviren indeks bir LSI değil, GSI'dir çünkü
bölüm anahtarı değişir. Ve buradaki her okuma bilinen bir anahtar üzerinde bir
Query ya da GetItem'dır — asla Scan tuzağı değildir.
Koşul ve anahtar ifadelerini DynamoDB Expression Builder ile oluşturun ve bir takip grafiğini kendi tablonuza karşı modellemek ve her iki yönün tek bir okumada çözülmesini izlemek için DynoTable'ı indirin.