DynamoDB'de Veri Nasıl Modellenir
SQL'de önce varlıkları ve ilişkileri modeller, sonra istediğin her şeyi daha sonra bir araya getirmesi için sorgu planlayıcısına güvenirsin. DynamoDB bunu tersine çevirir. Yapacağını zaten bildiğin okumaları modellersin ve anahtarlar bunlara hizmet etmek için vardır.
Join motoru yok ve çalışma zamanında bir strateji seçen planlayıcı yok. Bir Query tek bir anahtar boyunca tek bir partition okur ve tüm performans sözleşmesi budur. Bu yüzden anahtarları, derli toplu bir şema için değil, bilinen erişim desenleri için tasarlarsın.
AWS bunu best-practices kılavuzunda açıkça söyler: "yanıtlaması gereken soruları bilmeden şemanı tasarlamaya başlamamalısın."
Bu kılavuz, tüm süreci tek bir alan üzerinde işler: oyuncuları, oynadıkları maçları ve sezon başına sıralamalarını takip eden bir çok oyunculu oyun liderlik tablosu. Bir soru listesinden çalışan bir anahtar şemasına gideriz.
DynamoDB'de veri nasıl modellenir?
Önce tabloları değil, okumaları modelleyin. Uygulamanın yaptığı her sorguyu listeleyin, ardından her sorunun tek bir Query veya GetItem'a çözülmesi için bir partition key ve sort key tasarlayın. Birlikte okunan öğeleri birlikte konumlandırın, sort key'de değerler üzerinde aralık okuyun ve temel tablonun karşılayamadığı her erişim deseni için bir GSI ekleyin.
- Önce tabloları değil, okumaları listele. Sorular spec'tir; isimler bir dikkat dağıtıcıdır.
- Her soru tek bir
QueryveyaGetItemolmalı. Bir soru birScangerektiriyorsa, model yanlıştır. - Birlikte konumlandırılan öğeler bir partition key paylaşır; üzerinde aralık okuduğun her şey sort key'e girer.
- Temel tablonun yanıtlayamadığı bir soru bir GSI alır — asla filtreli bir
Scandeğil.
Adım 1 — Problemi tablolar olarak değil, sorular olarak çerçevele
players, matches ve scores tablolarını çizme dürtüsüne diren. O içgüdü SQL alışkanlığıdır ve burada yanlıştır. Bunun yerine, uygulamanın gerçekte gerçekleştirdiği her okumayı yaz. Liderlik tablomuz için:
- Bir oyuncunun profilini id ile getir.
- Bir oyuncunun son maçlarını listele, en yeni ilk.
- Belirli bir sezon için, puana göre sıralanmış en iyi N oyuncuyu göster.
- Bir oyuncuyu genel kullanıcı adıyla ara (örn. bir profil URL'si için).
Bu dört soru — isimler değil — spec'tir. Her biri tek bir Query'ye (veya GetItem'a) çözülmeli, çünkü DynamoDB'nin ölçekte ucuza sunduğu tek erişim şekli budur.
Bir soruya yalnızca tabloyu tarayarak yanıt verilebiliyorsa, model yanlıştır ve bunu gecikmede ve maliyette hissedersin — bir Scan'in neden kaçınılması gereken ayak tuzağı olduğunu görmek için bkz. Query ve Scan.
Tüm yöntem, alan başına bir kez çalıştırdığın kısa, sıralı bir boru hattıdır:
Aşağıdaki her adım bir kutuyla eşleşir: listele, say, anahtarları tasarla, geri kalanı için index ekle, sonra doğrula.
Adım 2 — Modellediğin ilkel yapıları anla
Bir tablonun, bir öğenin hangi fiziksel partition'da yaşadığını seçen bir partition key (PK) ve öğeleri o partition içinde sıralayan opsiyonel bir sort key (SK) vardır.
AWS core-components dokümanları bu çifti öğenin birincil anahtarı olarak adlandırır. Bir Query her zaman tam olarak bir PK değerini hedefler ve SK üzerinde aralık-tarama yapabilir veya filtreleyebilir — tüm araç takımı budur.
Bu tek-partition tasarımı, DynamoDB'nin 2007 Amazon Dynamo makalesinde ilk kez tanımlanan öngörülebilir, düşük gecikmeli, yatay olarak bölümlenmiş okumaları sunmasını sağlayan şeydir.
İki sonuç aşağıdaki her kararı yönlendirir:
- Birlikte okunan öğeler bir partition key paylaşmalı ki tek bir
Queryonları tek bir faturalandırılan istekte döndürsün. - Üzerinde aralık okumak istediğin her şey (son maçlar, en yüksek puanlar) sort key'de yaşamalı, çünkü
Query'nin sıralayabileceği ve sınırlayabileceği tek attribute budur.
Bir soru, temel tablonun sağladığından farklı bir erişim şekli gerektirdiğinde, bir Global Secondary Index eklersin — tablonun farklı bir PK/SK altında yeniden yansıtması.
(GSI ve Local Secondary Index karşılaştırması için bkz. GSI ve LSI.)
Adım 3 — Anahtarları her seferinde bir soruyla tasarla
Genel, aşırı yüklenmiş anahtar attribute'larıyla tek bir tablo kullanırız — single-table yaklaşımı — çünkü bir oyuncu ve maçları birlikte okunur.
Kendi öneklerini icat et; burada PLAYER#, MATCH# ve SEASON#, aksi takdirde genel olan anahtarların içinde varlık türünü etiketler.
Soru 1 ve 2 (profil + son maçlar) bir partition paylaşır, bu yüzden ikisi de aynı PK'ye asılır:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231", profili ve her maçı tek bir okumada döndürür. Yalnızca profil için, GetItem.
Son maçlar için, ScanIndexForward = false ile rangeId begins_with "MATCH#" onları en yeniden başlayarak dolaşır — sort key'deki zaman damgası sıralamayı bedava yapar.
Soru 3 ve 4 o partition'dan yanıtlanamaz — sezon sıralaması ve kullanıcı adı üzerinden döner, hiçbiri temel PK değildir. Her biri bir GSI alır.
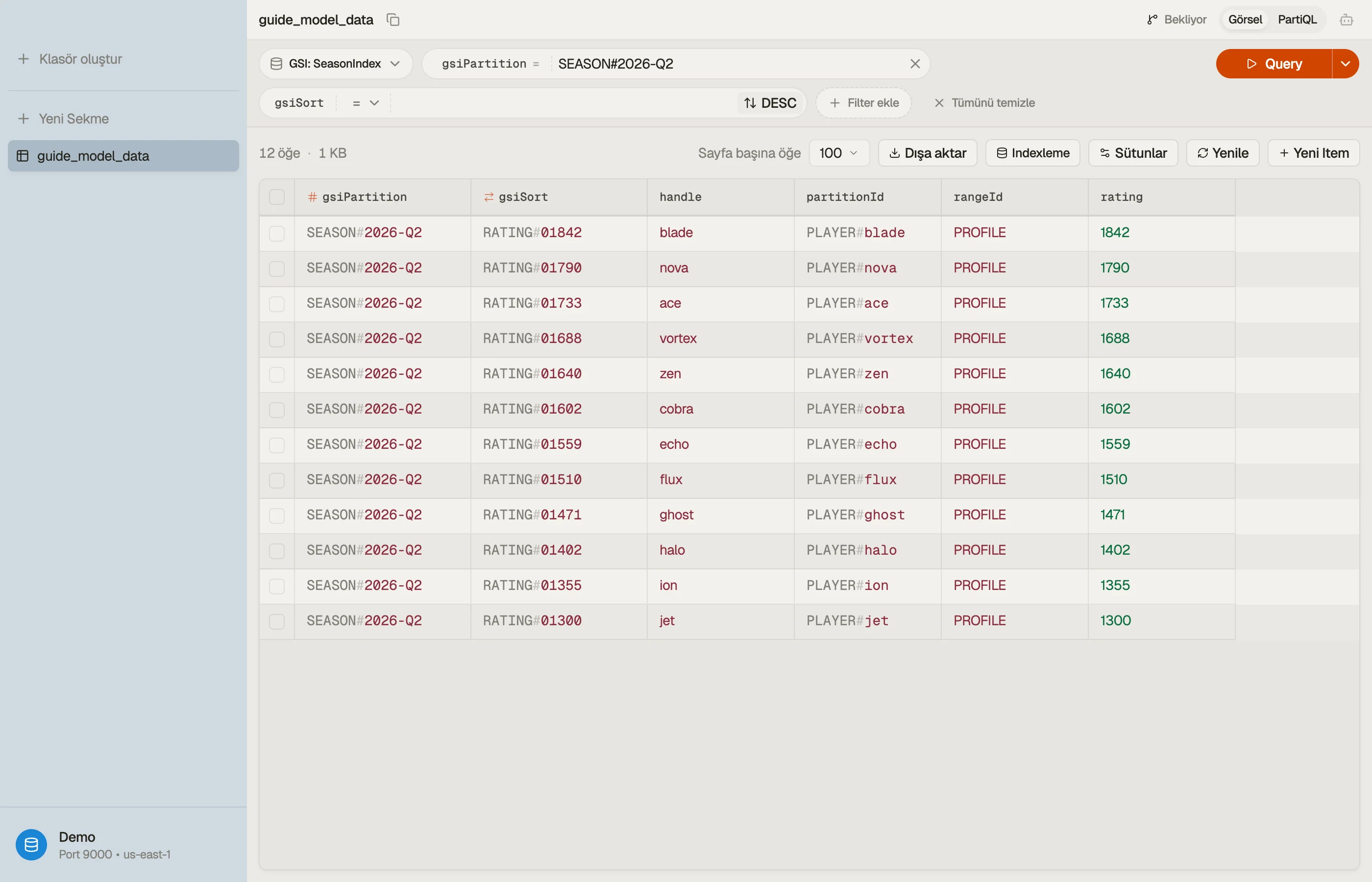
İki genel index attribute'u, gsiPartition / gsiSort ekleriz ve her öğenin onları o index'in ihtiyaç duyduğu şeyle doldurmasına izin veririz:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
Artık ScanIndexForward = false ile sezon index'ini WHERE gsiPartition = "SEASON#2026-Q2" Query etmek, oyuncuları puana göre sıralanmış döndürür — işte liderlik tablosu.
HANDLE#… üzerinde anahtarlanmış ikinci bir index, genel bir kullanıcı adını tek bir okumada bir oyuncu id'sine çözer. Tek bir fiziksel tablo, dört adet tek-Query erişim deseni.
RATING#1842üzerine bir sıfır-doldurma notu: DynamoDB, sort key'leri sayısal değil sözlüksel (lexicographically) olarak sıralar, bu yüzden bir puan sabit bir genişliğe sıfırla doldurulmalı (RATING#01842) yoksa9,1000'den sonra sıralanır. Bu, en baştan doğru yapmaya değer klasik bir modelleme tuzağıdır.
Adım 4 — Modeli DynoTable'da doğrula
Bir anahtar şeması, yalnızca gerçek bir Query'nin tam olarak beklediğin öğeleri ve fazlasını değil döndürdüğünü izlediğinde güven kazanır.
Tabloyu DynoTable'da aç, liderlik tablosu sorgusunu sezon index'ine karşı çalıştır ve partition'ın sıralanmış ve sınırlandırılmış olarak geri geldiğini doğrula — Scan yok, istemci tarafı sıralama yok.


Bu sorgular için koşul ifadelerini oluştururken — begins_with, gsiPartition = :p, placeholder :p bağlaması — bunu DynamoDB Expression Builder yapsın.
KeyConditionExpression'ı, ExpressionAttributeNames'i ve ExpressionAttributeValues'ı üretir, böylece result gibi bir rezerve kelime veya yanlış yazılmış bir placeholder bir okumayı asla sessizce bozmaz.
Adım 5 — Tuzaklar ve sonraki adımlar
Modeli yayınlamadan önce kontrol edilecek birkaç tuzak:
- Birlikte hiç okumadığın ilişkileri modelleme. Soru başına bir GSI ucuzdur; boşa harcanan bir GSI yinelenen bir maliyettir. Index'leri spekülatif olarak değil, soru listesinden ekle.
- Partition ısısına dikkat et. Bir PK (bir ünlü oyuncu, tek bir sıcak sezon) trafiğin çoğunu emerse, o partition kısılabilir (throttle). Bir anahtar kanıtlanabilir şekilde sıcak olduğunda yazmaları bir sonek parçasıyla (suffix shard) yay — AWS bunu partition-key tasarımı altında işler.
- Bir sort key'deki sayısal veya zamansal her şeyi sıfırla doldur ve ISO-8601 yap, böylece sözlüksel sıralama kastettiğin sırayla eşleşsin.
- Yeni bir soru = yeni bir anahtar veya index, asla bir
Scan. Gerçekten yeni bir erişim deseni daha sonra ortaya çıktığında, anahtarları genişlet; bunun üzerini bir filtreyle örtme.
Önce soruları modelle, anahtarları her biri tek bir Query olacak şekilde tasarla, sonra kanıtla.
Tablonu taramak, bu sorguları temel tabloya ve GSI'lere karşı yan yana çalıştırmak ve tasarladığın erişim desenlerinin tam olarak planladığını döndürdüğünü izlemek için DynoTable'ı dene.