筛选与查询模式
每个表标签页都携带一个筛选:即 DynoTable 转换成 DynamoDB 请求的谓词状态。搞懂这些组成部分如何映射为 query 与 scan,正是让这款应用又快、又让你账单更省的关键所在。
本页介绍可视化标签页模式。若要直接编写 SQL 风格的查询,请切换到 PartiQL;若需要连接与聚合,请打开一个 Workbench。
筛选行
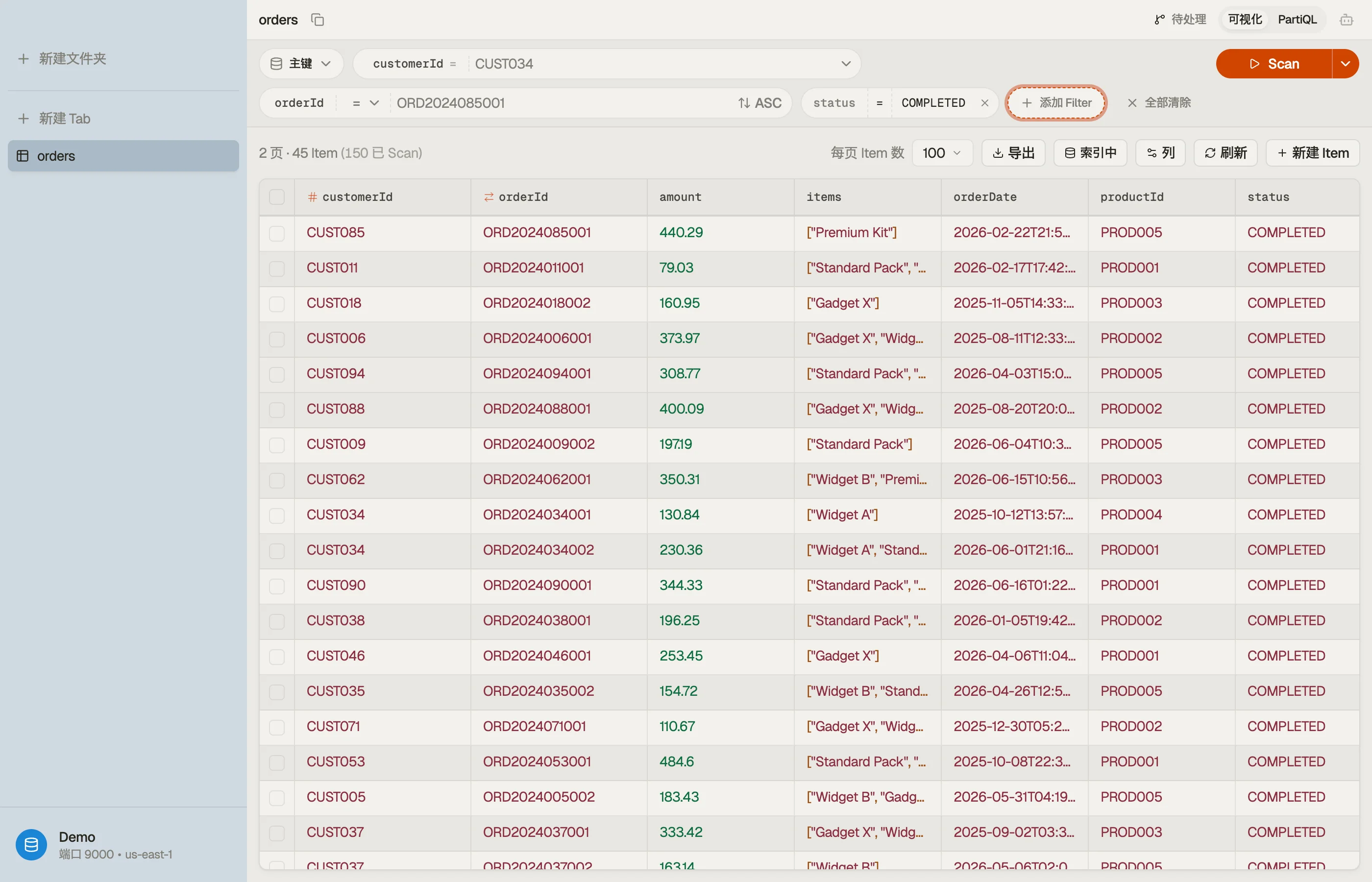
可视化模式会显示单行水平排列的胶囊:
[Index] [hashKey = value] [rangeKey op value] [+ filter] | [Clear] [Query/Scan]- 索引胶囊 —— 你所通过读取的查询模式。
- 键胶囊 —— 该模式的分区(哈希)键,以及在存在时的排序(范围)键。
- 筛选胶囊 —— 额外的非键条件(扫描筛选)。
- 操作按钮会根据你的设置显示为 Query 或 Scan,并在结果开始流式返回后变为 Load more。
设定一个值后 DynoTable 会自动执行;清除或编辑某个胶囊后,一旦筛选再次有效便会重新运行。


查询模式
查询模式是你所通过读取的索引:
PRIMARY—— 表自身的 / 。- 一个命名的 或 —— 其各自的键模式。
所选模式决定了你可以对哪些键进行筛选。从索引胶囊切换模式;键胶囊会随之更新为该模式的分区键和排序键。
Query 与 Scan
这是对成本和速度至关重要的区别:
- 设定一个 筛选,DynoTable 就会发出一次有针对性的 —— 它只读取匹配的分区。又便宜又快。
- 没有它时,它会退回为一次 ,即逐页读取整张表(或索引)。操作按钮会显示为 Scan 以明确这一点。
键筛选
分区键胶囊接受一个值;一旦设定,操作便变为 Query。排序键胶囊会在其之上添加一个比较:
=、<、<=、>、>=—— 有序比较(数字,以及字符串的字典序)。begins_with—— 对字符串或二进制的前缀匹配。between—— 一个闭区间范围;该胶囊会长出第二个值字段。
字符串类型的键提供自动补全:当 DynoTable 在后台为一张表建立索引时,它会建议你已经见过的真实值。没有有用建议的键(比如随机 UUID)则回退为普通输入框。
扫描筛选
+ filter 胶囊会添加一个非键条件 —— 任意属性,而不仅仅是键。每个筛选由一个列、一个运算符和一个值组成:
- 比较:
=、≠、<、<=、>、>=、between。 - 成员关系:
in—— 匹配列表中的任意值(字符串或数字)。 - 字符串 / 二进制:
begins_with、contains。 - 存在性:
exists、not exists。 - 类型:
type equals/type not equals(针对 DynamoDB 类型代码 ——S、N、BOOL、…),外加用于集合类型的size系列。
所提供的运算符会因属性的类型而异 —— 排序比较出现于数字,begins_with 出现于字符串。扫描筛选在 query 或 scan 读取条目之后才应用,因此它们会收窄结果,但不会让一次 scan 更便宜。用键筛选来减少读取;用扫描筛选来精炼返回的内容。
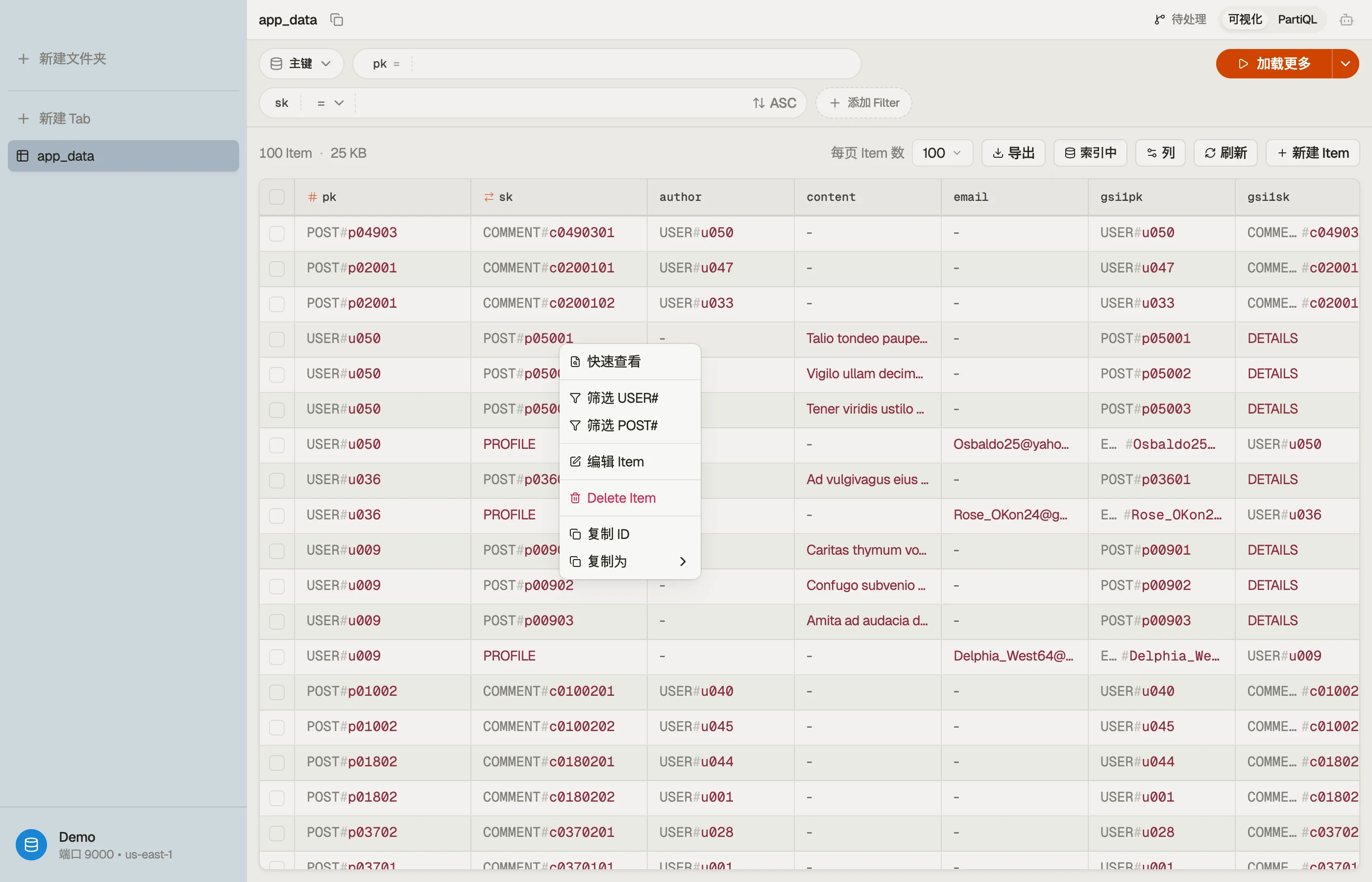
单表设计:复合键
单表设计将多种实体类型借助键前缀打包进同一张表 —— USER#123、ORDER#456、TENANT#acme。DynoTable 会自行识别它们,无需任何设置:
- 键就地解码。 一个复合值 —— 一个大写前缀通过
#、|或~与其余部分相连 —— 会在每个网格中渲染为其带标签的各部分:表、PartiQL 结果以及 Workbench。仅仅碰巧包含其中某个字符的普通值(例如#FF5733这样的十六进制颜色,或一个以竖线分隔的列表)则原样保留。 - 一键筛选到某个实体。 右键点击某一行并选择 Filter to
USER#—— 该前缀直接从那一行的键中读取。DynoTable 会对该键应用一个真实的begins_with,作为一个普通筛选胶囊,你可以用通常的方式(它的 ✕,或 Clear)将其清除。当某一行的分区键和排序键都带有前缀时,你会为每一个各得到一个选项。
没有对话框、没有配置、也不保存任何东西 —— 它完全是从你眼前的键实时推导而来。


排序与分页
排序键胶囊带有一个排序方向切换(升序 / 降序),它映射到 DynamoDB 的 ScanIndexForward。结果会一次一页地流式返回 —— Load more 会取下一页,而更改页大小会从第一页重新加载。
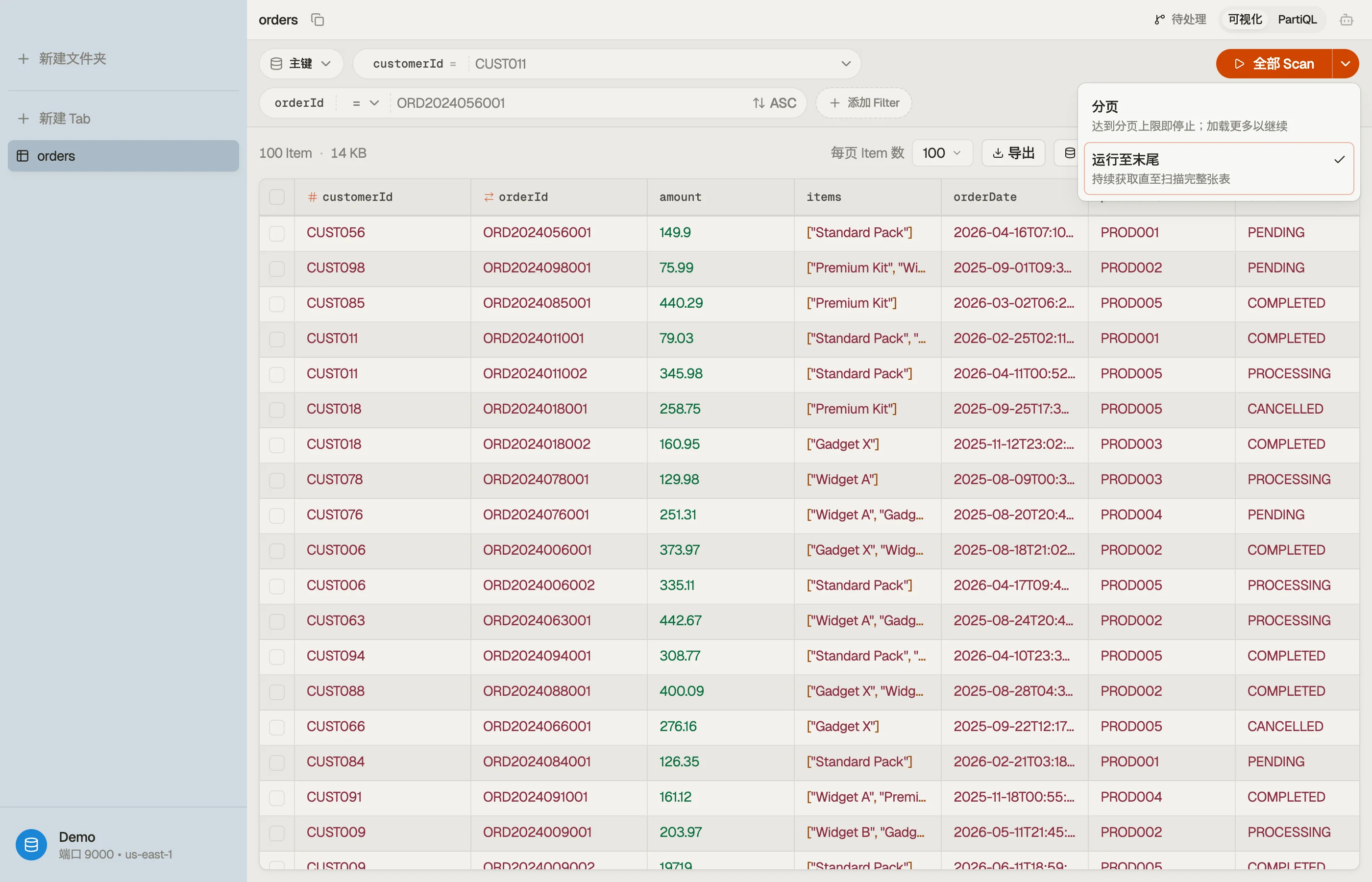
运行到底
默认情况下,一次 query 或 scan 会在若干页之后暂停,这样一张大表就不会一次性全部加载 —— 操作按钮会显示 Load more 以取下一页。当你更希望一次性拉取全部内容时,请切换运行模式:
- 点击操作按钮旁的 chevron 并选择 Run to end。主按钮会重新标注为 Scan all / Query all / Run all —— 包括当你在页预算处暂停时,点击它会一直读取到底。
- 点击那个重新标注的按钮,DynoTable 会持续取页,直到读完整张表(或索引)。该选择会按标签页在本次会话内被记住;选择 Paged 即可切回。选择某个模式本身绝不会启动一次运行 —— 它只是重新标注按钮,因此由你来决定何时触发。
在大表上,开启运行到底时会先显示一个确认提示,其中给出该表的近似大小和条目数,因此一次完整扫描始终是一个有意为之的选择,而非意外之举。确认以继续,或取消以保持分页。


通过键盘:
- ⌘↩ 运行当前查询 —— 而当结果在页预算处暂停时,它会继续到下一页而不是从头开始。
- ⌘⇧↩ 始终一次性运行到底。
- ⌘. 或 Esc 可随时停止一次进行中的运行。